
SPP(Spatial Pyramid Pooling)
论文链接:https://ieeexplore.ieee.org/document/7005506
让不同的输入维度有同样的维度的输出,就是SPP所实现的。
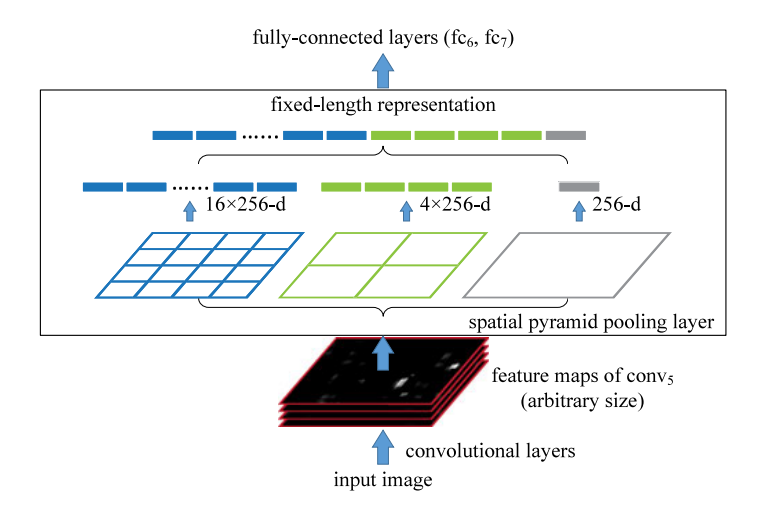
如上图
假设输入特征图是 x x ,
第一次直接对整个图池化,得到就是 x x ,
第二次将图像分成4份,对每一份都池化,得到的就是4个 x x ,
第二次将图像分成16份,对每一份都池化,得到的就是16个 x x ,
然后将21个 x x 拼接,就有 x x ,
输出结果完全和输入的,无关。
Atrous Convolution(空洞卷积)
空洞卷积其实就是卷积计算时“镂空”,类似这样子:
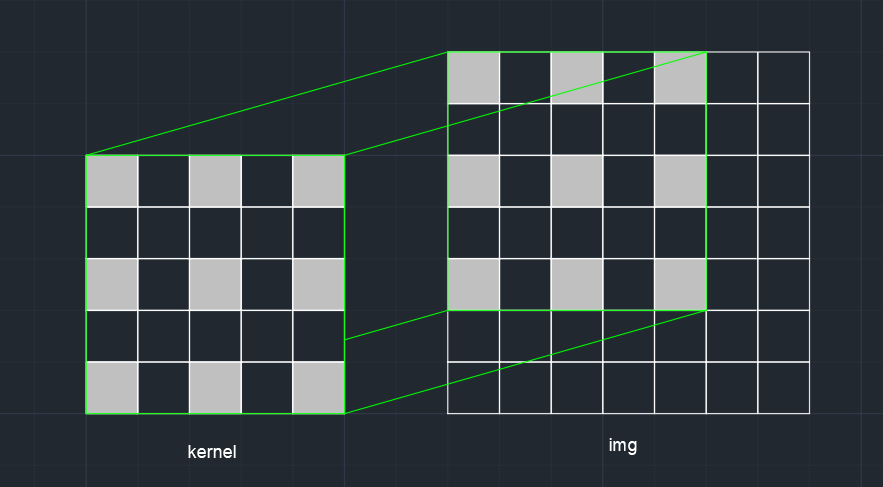
上图是采样率(dilation rate)为2的空洞卷积,其实也就是间隔。正常卷积其实就是采样率为1的空洞卷积。
在神经网络中,为了增加感受野且降低计算量,我们总会进行下采样,
但是这样虽然可以增加感受野,但空间分辨率降低了。
空洞卷积可以尽量不丢失分辨率的情况下仍然扩大感受野。
假设一张图片 x ,经过一个 x 的卷积,再过一个pooling,结果是 x 。
假设一张图片 x ,经过一个 x 的空洞卷积,结果是 x 。
而且常常空洞卷积会伴随着padding,所以输出分辨率也会保留更高。
所以空洞卷积相对于普通卷积再过池化,结果分辨率更高,扩大感受野。
空洞卷积还有一个好处就是可以通过设置不同的采样率,捕获多尺度信息。
但是空洞卷积也有缺点。也就是gridding(网格效应/棋盘)问题。
因为很明显空洞卷积每一个提取出来的特征,其实在原图像都是不连续的。
它会导致局部信息丢失以及获取的远距离信息缺乏相关性。
有一个较好的解决方法,叫做HDC(Hybrid Dilated Convolution)。
论文链接:https://ieeexplore.ieee.org/document/8354267
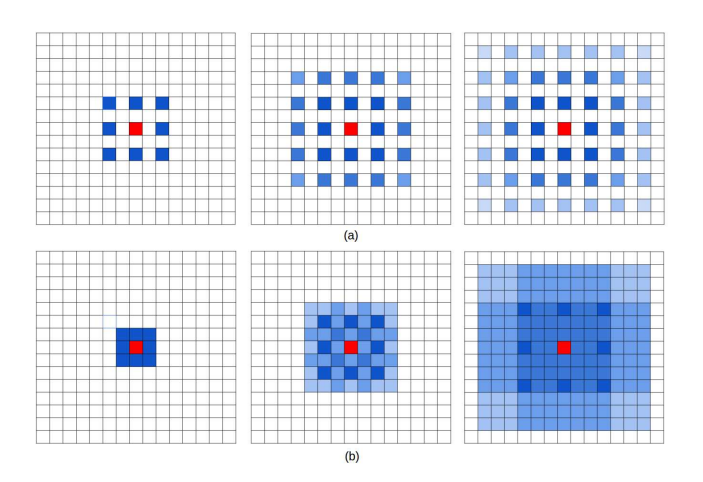
其实也很好理解,原来的卷积区域相当于是一个格子往八个方向各走dilation_rate格。
现在相当于先走一格,相当于普通卷积。(dilation_rate=1)
然后对这个普通卷积的区域,也就是这九个格往八个方向各走两格。
因为有9个格子,所以就有重复,没有空缺。(dilation_rate=2)
然后对这四十九个格往八个方向各走三格。(dilation_rate=3)
这样子卷积后的结果既有连续信息,也有跨越的信息。
参考:https://zhuanlan.zhihu.com/p/50369448
ASPP(Atrous Spatial Pyramid Pooling)
Deeplab v2论文链接:https://arxiv.org/abs/1706.05587
ASPP是在SPP的基础上,用Atrous Convolution(空洞卷积),增加了感受野。
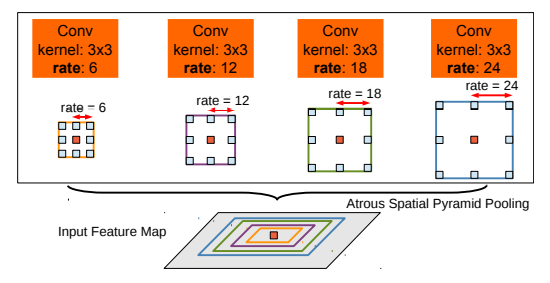
主要就是用了普通空洞卷积,没有用到HDC。
对一特征图用不同dilation_rate的空洞卷积,然后拼接到一起。
控制padding保证输出特征图维度不变,例如:
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=6, dilation=6)
参考:https://blog.csdn.net/m0_37798080/article/details/103163397